Himmelfarb Library’s Scholarly Communications Committee is pleased to announce five new short video tutorials have been added to our video library! This video library now includes 30 short 3-7 minute videos on a variety of scholarly publishing topics, perfect for microlearning! This round of new videos covers topics including human participant research support, addressing health misinformation and disinformation, using Dimensions Analytics, Cabells Journalytics, and finding an author’s H-Index using Google Scholar and Scopus.
Are you interested in learning more about the resources available to support human participant research at George Washington University? This video includes information about the Office of Human Research (OHR), Institutional Review Boards (IRB), and CITI Training available through GW in this short three and half minute video.
This five-minute video discusses how to address health mis- and disinformation. Learn the difference between mis- and disinformation, the different types of mis- and disinformation, why this matters in relation to healthcare providers and health literacy, and how to address mis- and disinformation with patients.
Dimensions, a database from Digital Science, tracks research output and has information about grants, publications, datasets, clinical trials, policy documents, and more. This tutorial provides a brief overview of Dimensions Analytics, which allows you to track and visualize research output trends, and allows for more comprehensive functionality. Several examples of use cases are also included.
This five-minute tutorial provides an overview of Cabells Journalytics, a tool that can be used to evaluate and compare journals in which to publish a manuscript. Learn how to access Cabells Journalytics, and see example journal records to see the depth of information provided about each journal. You’ll also learn how to compare up to five journals.
In this five-minute tutorial, you’ll learn more about what the H-Index is (a measure of both quantity and quality of research output) and how it is used to track researcher productivity. This tutorial will then walk you through how to find an H-Index using both Google Scholar and Scopus, and why there is sometimes a difference in the H-Index value between these two sources.
This newest installment of videos is part of the Scholarly Communications Committee’s Short Video Series, which covers a wide range of scholarly communications-related topics and covers all phases of the research life cycle. Have a scholarly publishing topic that you’d like us to discuss? We’d love to hear from you! To suggest a topic for an upcoming video, please contact Sara Hoover at shoover@gwu.edu.
To learn more about scholarly publishing, check out our Scholarly Publishing Guide. This guide includes resources to help scholars find an appropriate journal in which to publish their research, tips on how to spot and avoid predatory publishers, and information on how to promote and increase the visibility of your published research.
With the new 2023 NIH Data Management and Sharing Policy scheduled to take effect in January 2023, file naming conventions are an important piece of the data management puzzle. This new policy encourages project teams to agree on file naming conventions for objects and files and follow file naming convention best practices. This post will explore current best practices for file naming conventions.
Why Use Standardized File Naming Conventions?
Creating standardized file naming conventions is an important part of the research process. Standard file names are a great way to keep your research organized while ensuring that files can be easily located and identified by everyone in the research group. Using standard file naming conventions will also help future users find and understand the data after the project has ended. Using standardized and descriptive file names will help streamline the workflow by helping users easily identify the contents of a file without having to open the file (Univ. of Michigan Library, 2022).
The best time to develop a file naming convention is before you start your research project. Having a file naming convention in place before you start the project will prevent your project from having a backlog of unorganized files, which can lead to misplaced or lost data (Longwood Research Data Management, 2022). Your research group should decide at the outset of your project what naming conventions will be used. Once a file naming convention has been agreed upon by the research group, it must be consistently followed by all members of the group. If the naming convention isn’t followed, data could become difficult to find, making it unusable.
What Should Be Included in File Names?
File names should be descriptive enough to capture relevant information about the file, so try to build two or three salient characteristics of the project and dataset into each file name (University of Michigan Library, 2022). Think about the types of files you’ll be working with and the types of information each file will contain when developing your file naming convention. For example, what groups of files will your naming convention cover? Are different naming conventions needed for different sets of files? Does your group, department, or discipline already have file naming conventions in place which could be used?
It’s also a great idea to think about the metadata you’d like to include in each file name. Consider what information should be included to allow users to easily and quickly locate or search for a needed file. Since computers arrange files by name, character by character, it’s a good idea to put the most important information at the beginning of the file name. If finding information by date is a priority, start each file name with a date (see the Standardized Dates section below for more information on using dates in file names). If the type of data is the most important piece of information, start each file name with the type of information instead.
Consider including the following pieces of information in your naming convention structure:
Unique identifiers (such as a grant number)
Project, study, or experiment name or acronym
Location information (such as spatial coordinates)
Researcher initials
Date or date range (in a standardized format)
Experimental conditions (such as instrument, temperature, etc.)
Version number (more information below in the Use Versioning section below)
Type of data (image, dataset, samples, etc.)
Family type, or file extension
Lab name or location
What Should be Avoided in File Names?
While many file naming best practices revolve around what should be included in a file name, there are also best practices related to what should not be included in file names. Here are the top three things to avoid in your file naming conventions:
Spaces: While separating metadata elements is a common practice, avoid using spaces to separate each element. Consider using dashes or underscores instead of spaces. For example, instead of using File Name.xxx, consider using File-Name.xxx or File_Name.xxx instead. You could also consider not separating metadata at all, and using Camel Case to eliminate spaces: FileName.xxx
Special Characters: Avoid using special characters such as @ # $ % & * in file names. Limit file names to alphanumeric characters.
Long File Names: In general, file names should be kept to 30 characters or less. Shorter file names will make it easier for users to identify the contents of the file. Longer file names may not be readable by software programs.
Standardizing Dates
When including dates in file names, using International Organization of Standardization (ISO) standards is generally considered to be the best practice. Dates should be formatted starting with the four-digit year, followed by the two-digit month, and two-digit day:
YYYYMMDD (ex: 20221021)
YYYY-MM-DD (ex: 2022-10-21)
Use Version Control!
Many research projects involve creating and maintaining multiple versions of the same file. If this is the case for your research project, be sure to use versioning to indicate the most current version of files. Using file versioning not only helps you keep track of which file is the most recent update, but it also provides you with the ability to revert data to an earlier version without starting from scratch or having to regenerate data (Cornell University, 2022).
Some tools such as electronic lab notebooks or Box allow you to assign version numbers, but you can create version control by building versioning into your file naming convention. You can track versions by adding version information to the end of a file name. Here’s an example:
File_Name_v001.xxx
File_Name_v002.xxx
File_Name_v003.xxx
You can also include the date to indicate a version number:
File_Name_20220213.xxx
File_Name_20220321.xxx
File_Name_20220601.xxx
Avoid using ambiguous labels, such as “revision” or “final” in your file names. It’s also a good idea to save your original, untouched raw data and leave it that way. Having this raw data saved will allow you to always have the original data as a safe, untouched copy.
Standardized Numbers - Use a Leading 0!
If sequential numbering is part of your file naming structure, use leading zeros. For example, instead of using 1, 2, 3, use 001, 002, 003. This will ensure that your files will be sorted in an easily findable manner. This applies to version control numbering as well.
Directory Structure Naming Conventions
File naming conventions don’t just apply to your files, use the same best practices to structure your directory folders as well. Directory folders should provide key information about the file contents stored within each folder. Be sure to include the project title, unique identifiers, and the date. It might be helpful to create a brief description of the content stored in major folders and to provide an overview of the directory structure in your documentation. The level of detail included should be enough to help someone understand the contents and organization of the files.
Here’s a nice example: (Cornell University, 2022)
Top Folder: Study_name
Subfolder1: Study_name_Datasets
Study_name_2019-2020.csv
Study_name_2021-2022.csv
Subfolder2: Study_name_Semanitc_analysis
Study_name_semantic_analysis.R
Study_name_semantic_analysis_output.csv
Readme File: Study_name_readme.txt
Document Naming Conventions
Be sure to document each file naming convention in a top-level readme file. This file should include instructions for navigating the structure so that others involved in the research project, and others who might use this data once the project is complete can follow the naming conventions used. This file can be a README.txt file and should be kept with your files.
File naming conventions are an essential part of any research project! Be sure to take the time to create a file naming convention that will help keep your files organized, easily findable, and usable by your research team and any others who may look at your data once your project is finished. Stay tuned for future posts on best practices related to other data management topics!
On August 25, 2022, the White House Office of Science and Technology Policy (OSTP) published a memorandum that updated guidance on research funded by federal grants and called for the end of a 12-month embargo period. By 2025, published research that is funded by the federal government must be made available to the general public and key stakeholders and must no longer reside behind a paywall. Government agencies, academic libraries, and other research institutions are in the process of understanding this memo and updating their policies. Many institutions believe this new memo and guidance will radically change the academic publishing landscape. While this policy will likely advance a cultural shift towards open sciences, there are also likely new challenges related to the publication lifecycle that researchers are likely to encounter. In this post, we’ll provide a detailed explanation of the OSTP’s guidance, how this will impact researchers, and offer library resources to help prepare for the change.
“Update their public access policies as soon as possible, and no later than December 31st, 2025, to make publications and their supporting data resulting from federally funded research publicly accessible without an embargo on their free and public release;
Establish transparent procedures that ensure scientific and research integrity is maintained in public access policies; and,
Coordinate with OSTP to ensure equitable delivery of federally funded research results and data.” (Office of Science and Technology Policy, 2022, p. 1)
Dr. Alondra Nelson, Deputy Assistant to the President, explained later in the memo that “The insights of new and cutting-edge research stemming from the support of federal agencies should be immediately available–not just in moments of crisis, but in every moment. Not only to fight a pandemic, but to advance all areas of study, including urgent issues such as cancer, clean energy, economic disparities, and climate change” (Office of Science and Technology Policy, 2022, p. 2-3). Under the OSTP’s new guidance, researchers, journalists, members of the public, and other interested parties will be able to access new research as soon as it is published at no additional cost. This will provide the public with the opportunity to learn more about new innovations and experiments and it will allow other researchers to replicate or expand on existing research.
The new guidance will allow for more collaboration as researchers combat complex topics such as climate change, future pandemics, and other global concerns. New research and data will be made freely available to the public, so researchers and institutions will need to address how to handle publication processing fees. While this new guidance won’t go into effect until 2025 and there are still questions about how specifically it will alter existing public access policies at government agencies like the NIH, the staff at Himmelfarb are here to assist researchers who may have questions about how the OSTP memo will impact their work.
With the 2023 NIH Data Management and Sharing Policy going into effect on January 25, 2023, there’s no better time to explore data management resources! This post explores resources that can help you with your data management needs.
What is data management?
Data management involves the process of collecting or producing, cleaning and analyzing, preserving, and sharing data from a research project. Data management takes place throughout the entire research life cycle, from deciding on consistent file naming conventions to depositing the data in a repository for long-term archiving.
Why Data Management?
Data management is vital for transparency (showing your work promotes reproducibility of work), compliance (funding organizations and journals often require making data available), and personal and organizational benefit (using data within your own lab is easier with proper management).
I Think It’s FAIR to Say…
Understanding data management best practices is important to make well-informed decisions when selecting data management resources and tools. The FAIR Principles, first published in 2016, provide a set of guidelines for data management. FAIR stands for Findable, Accessible, Interoperable, and Reusable. You can learn more about the FAIR Principles on our Data Management Guide. Another great resource to help guide your data management is Cornell University’s Research Data Management Service Group’s Comprehensive Data Management Planning and Services Best Practices which provides extensive information related to best practices for:
Himmelfarb’s Data Management Guide provides a wealth of information and resources related to data management. In addition to some basic information about data management, you’ll find information about NIH and NSF funder requirements. Data management plans (DMPs) are also covered in detail. The documentation and metadata page explains what metadata is, what should be included in your metadata, metadata schemas, controlled vocabularies, file naming conventions, and electronic lab notebooks. The data storage and security page includes data storage, storage formats, creating a backup plan, and data security. You’ll also learn about data sharing, including GW’s policy on regulated information, and data repositories.
I might need to make a plan for this…
Creating a data management plan (DMP) is often part of the grant writing process required by funding institutions. A comprehensive data management plan should address:
Data Collection: Must be reliable and valid.
Data Storage: Appropriate amount of data so research can be reproduced.
Data Analysis: Interpretation of data from which conclusions can be derived.
Data Protection: Ensuring sensitive data is safe and secure, preventing tampering or loss of data.
Data Ownership: Addresses legal rights associated with data.
Data Retention: Addresses how long data should be kept and proper disposal of sensitive data.
Data Reporting: Publication of data.
Data Sharing: Addresses what data can be shared with others and how.
When it comes to creating a DMP, there are a number of tools available to help! The DMPTool is a free, open-source tool that helps researchers create DMPs that comply with funder requirements. DMPTool also provides links to funder websites, and best practices resources to help guide your data management efforts. Since GW is affiliated with DMPTool, GW users can create a personalized dashboard that allows them to see and organize the DMPs created through the tool. From the DMPTool’s website, simply click “sign in” and use Option 1 to search for George Washington University. Then log in with your GW UserID and password and create your data management plan!
The Framework for Creating a Data Management Plan, created by ICPSR, is a great outline that will help you create a DMP for your grant application. The framework includes a list of elements to be included, explains why each element is important and provides examples for each element. Michener’s article Ten Simple Rules for Creating a Good Data Management Plan is another great starting point to gain an understanding of the principles and practices of creating a DMP and ensuring your data are safe and shareable. For more DMP resources and to see examples and templates, check out the Data Management Plan page of the data management guide.
What’s Next?
Stay tuned for future posts on best practices for writing a data management plan, data storage, file naming conventions, creating “readme” metadata, and other data management topics. In the meantime, check out the lists of GW resources and additional resources below to learn more!
Image credit National Institute on Aging, NIH: Brain Inflammation from Alzheimer’s Disease (CC BY-NC2.0)
Last month, Science published a story describing how images used in some highly cited Alzheimer’s research papers were discovered to be manipulated.1 These publications supported the amyloid beta (Aβ) hypothesis of Alzheimers which links the disease to protein deposits forming plaques in brain tissue. The research spurred drug development targeting Aβ oligomers. Many of the manipulated images were the work of a neuroscientist named Sylvain Lesné who discovered the Aβ*56 oligomer and claimed that it caused dementia in transgenic mice in a landmark Nature study published in 2006.2
The Nature paper has been cited in about 2300 scholarly articles—more than all but four other Alzheimer’s basic research reports published since 2006, according to the Web of Science database. Since then, annual NIH support for studies labeled “amyloid, oligomer, and Alzheimer’s” has risen from near zero to $287 million in 2021.
Piller, C. Blots on a field? Science 377:6604, 360 (2022).
The image manipulation was first discovered by a fellow Alzheimer’s researcher named Matthew Schrag who was hired by an attorney investigating possible fraud in the development of Simufilam, an experimental Alzheimer’s therapy. Schrag found altered or duplicated Western blot images in dozens of research articles on the drug and its underlying science, including the Nature study. He stopped short of calling the manipulations deliberate misconduct, saying he would need the original unpublished images to prove that. Shrag reported his findings to the NIH which had funded much of this research, and the journals that published the works.
Schrag also reached out to Science Magazine, fearing that the NIH and the journals would not conduct their investigations fast enough to prevent more potentially wasted grant funding and research. Science conducted a 6 month investigation led by independent image analysts and several Alzheimer's researchers who concurred with Schrag’s findings. They describe “shockingly blatant” instances of image tampering, including piecing together images from different experiments.
More than 20 suspect Lesné papers have been identified. Lesné submitted corrected images for a few, but even those corrections have shown signs of manipulation. 13 papers including the Nature study are now under investigation by the journals they were published in. Schrag and others have been critical of Karen Ashe, the head researcher where Lesné did his initial work on Aβ*56, saying she did not do enough to ensure the integrity of the research coming out of her lab.
Journal publishers do not typically use sophisticated image analysis to determine if images have been tampered with. The Materials Design Analysis Framework was developed by several publishers in 2021 to improve data transparency and help prevent image manipulation. The Committee on Publication Ethics (COPE) provides standards for publishers to follow on data and reproducibility and how to handle allegations of misconduct, but it does not sanction members who don’t follow guidance, as outlined in this Scholarly Kitchen editorial. The new NIH Data Management and Sharing policy which goes into effect in January 2023 should improve access to data and original images in NIH grant funded research, encouraging further scrutiny and reproducibility.
Retraction Watch can help you identify papers that have been flagged as retracted or under investigation. Our article on Searching for Retractions outlines sources and methods for finding retracted or corrected works so flawed findings are not included in future research or systematic reviews. Schrag used PubPeer in his investigations, a discussion space where researchers can report suspected issues with publications.
You can listen to an interview with Charles Pillar, the author of the Science article, detailing the magazine’s and Schrag’s investigations on the Science Magazine July 21 podcast.
Lesné, S., Koh, M., Kotilinek, L. et al. A specific amyloid-β protein assembly in the brain impairs memory. Nature 440, 352–357 (2006). https://doi.org/10.1038/nature04533
Selecting a journal in which to publish your research is an important decision. With so many journals from which to choose, it can be daunting to compare journals and avoid publishing in a predatory or questionable journal, all while trying to find submission requirements, peer review information, and author guidelines to inform your decision making process. GW users now have access to Cabells Directory of Publishing Opportunities which can help you compare journals and identify predatory journals to avoid!
GW’s access to Cabells includes access to Journalytics and Predatory Reports. The Journalytics portion provides information on reputable journal titles including manuscript and submission guidelines, discipline, intended audience, peer review information, and acceptance rates. This information can help authors compare journals and make an informed decision regarding where to submit a manuscript for publication. Inclusion in Cabells Journalytics is by invitation only and criteria for inclusion can be found in the Journalytics Selection Policy.
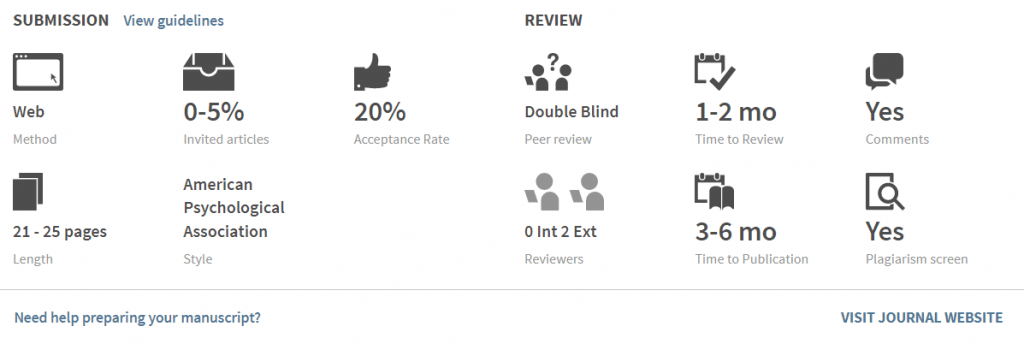
The screenshot below is an example of the submission and review information listed for the Journal of Advanced Nursing found in Cabells Journalytics:
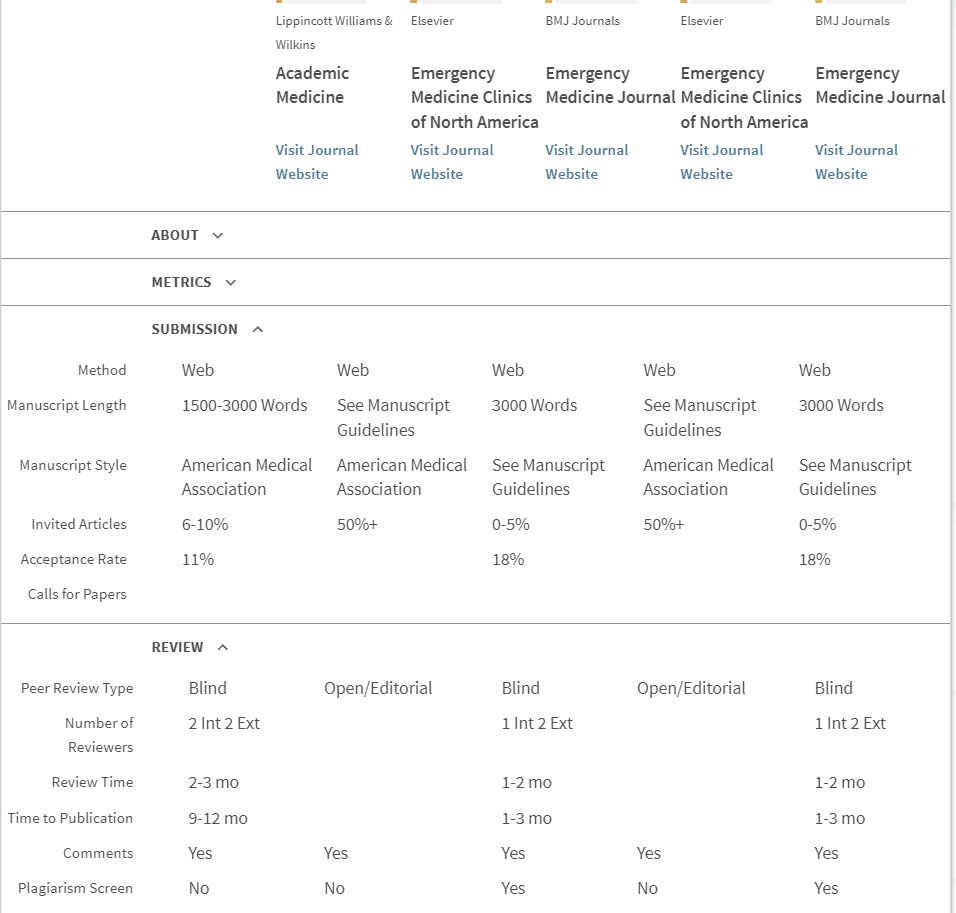
Journalytics also allows you to compare up to 5 journals by selecting the titles you wish to compare, and clicking on the “Compare 5” button at the top of the search results. The screenshot below shows a side-by-side comparison of 5 emergency medicine journals:
The Predatory Reports portion of Cabells tracks journal titles that have been associated with predatory journal publishers based on violations of scholarly publishing standards and best practices. Cabells has established criteria for identifying deceptive, fraudulent, and/or predatory journals and provides a list of violations for each title listed in Predatory Reports. Examples of severe violations include: false qualifications or credential claims; fake ISSNs; fake, non-existent, or deceased editors; false peer review claims; publication of non-academic or pseudo-science papers; false indexing claims; lack of published articles or archives; misleading metrics; and misleading or false fee information. Cabells provides access to the complete list of Predatory Reports Criteria on their website.
The screenshot below shows an example of a list of violations from a title listed on Cabells Predatory Reports:
If you’d like a second opinion, or are unable to find a title you are suspicious of listed on Cabells Predatory Reports, don’t hesitate to use Himmelfarb’s Predatory Journal Check-Up Service by contacting Ruth Bueter (rbueter@gwu.edu).
Whether you want to check to see if a journal in which you are interested in publishing could be a predatory journal, or you want more information about potential journals to which you might want to consider submitting your manuscript, Cabells Directory of Publishing Opportunities can provide you with the concise information you need all from a single, easy-to-use interface! To learn more, or if you have questions about this resource, contact Ruth Bueter (rbueter@gwu.edu).
Whether you’re a new Himmelfarb Library user, or have been using the library for years, chances are there are things you don’t know about us. We’d like to take this opportunity to help you get to know us, or get reacquainted with us and all that we have to offer!
Getting Help is Easy! Just Ask Us!
Whether you need help finding a specific full-text article, identifying a resource for your research, formatting a citation, or have a more in-depth question about conducting a literature review, a systematic review or managing your data, our reference librarians have the knowledge and know-how to help! Stop by our reference desk, chat with us using the “Ask Us” button on our website, call us (202-994-2850), email us (himmelfarb@gwu.edu), or text us (202-601-3525) for help. We look forward to answering your questions, large or small!
Our Collections
Himmelfarb has extensive collections that include 125+ databases, 6,700+ ebooks, and 6,500+ electronic journals that are available 24/7 from on and off-campus! We also have thousands of print books in our basement level stacks that are available for check out. Most books can be borrowed for three weeks. But don’t worry - if you need more time, you can renew most items twice by stopping by or calling our Circulation Desk (202-994-2962), or logging into your library account.
Remember that masking is still required in the library in accordance with GW’s current mask protocols. Please wear a mask while spending time in Himmelfarb for your own safety, and for the safety of those around you. Hand sanitizer is also available throughout Himmelfarb.
Himmelfarb Tour
Take a quick virtual tour of Himmelfarb to help you get acquainted with our space!
Study Rooms & IT Support
We have plenty of study rooms available on our second and third floors. Study rooms must be reserved and can be booked up to seven days in advance. The SMHS Technology Support Center is located on the third floor in the Bloedorn AV Study Center for all of your IT support needs.
Technology Resources
Himmelfarb’s Bloedorn Technology Center, located on our third floor, offers statistical software, including SPSS, Stata, SAS, NVivo, MATLAB, and Atlas.ti on select computers. We also have equipment such as digital camcorders and digital voice recorders for loan to support curricular development and activities, but these items must be reserved in advance.
All of Himmelfarb’s electronic resources are available 24/7 from anywhere! Just login with your GW UserID and password, or via the GW VPN. If you have trouble accessing any of our resources, reach out to us (himmelfarb@gwu.edu) so we can help troubleshoot, resolve issues and restore access as soon as possible.
Services and Support
Instruction:
We have services to help faculty and instructors use and connect Himmelfarb’s resources in the classroom. Our Durable Links Service will check, fix, or create new links to our resources that work from both on and off campus so your students will be able to access materials from anywhere. Our Course Reserves service provides access to electronic, print, and streaming course materials. Do you use a book in a course that Himmelfarb doesn’t currently own? Contact Acquisitions Librarian, Ian Roberts, and we will consider purchasing items for use in your courses.
Research Support:
Whether you are a faculty member, researcher, or student, Himmelfarb can help you be successful in your research! Are you working on your Culminating Experience project? Himmelfarb librarians provide individual consultations to help get your project started - and keep it going.
Are you working on a systematic review and could use some support? Check out our Systematic Reviews Guide for in-depth information on the process. Himmelfarb also provides access to Covidence, an online tool that streamlines parts of the systematic review process such as screening references, and creating and populating data extraction forms. You can also use our Systematic Review Service for additional librarian support!
Check out our tutorials for help with navigating databases, using specific software such as ArcGix, MATLAB, RefWorks, SPSS, or Camtasia, and for help with a wide array of research topics. Our Resources for Early Career Researchers Guide can help new researchers understand and navigate the research and publishing landscape. Check out our Scholarly Publishing Guide for information and resources related to publishing, researcher profiles, author rights, and measuring the impact of your research. Scholarly communications webinars and short tutorials are also available on this guide!
Himmelfarb Library Can Help!
Whether you are a student, faculty, or staff member, Himmelfarb Library has the resources and knowledge to help make your studies and research successful. From study space, extensive collections of resources, to expertise in systematic reviews and publishing, we have something for everyone!
Starting in January of 2023, NIH will put into effect a new Data Management and Sharing Policy for grant applications due on or after the 25th of that month. This will replace the existing policy which has been in place since 2003. The purpose of the new policy is to ensure that the data from NIH funded research is accessible and transparent, both to enable validation of research results and to make the data available for reuse. To see specifically what has changed, this NIH web page outlines the current and new policies side by side.
In order to help researchers prepare for the new policy, the NIH has a new website on data sharing. The website is meant to help researchers determine which policies apply to their projects and provide tools and resources to aid compliance. Below is a video which introduces the new website and how it can be used:
NIH will also present two webinars on the policy, starting with:
GW’s Himmelfarb and Gelman Libraries are preparing to assist researchers with questions about compliance. At Himmelfarb, you can contact Sara Hoover (shoover@gwu.edu), Metadata and Scholarly Publishing Librarian, and Paul Levett (prlevett@gwu.edu), Reference and Instructional Librarian. At Gelman you can contact Megan Potterbusch (mpotterbusch@gwu.edu), Data Services Librarian.
Himmelfarb Library’s Scholarly Communications Committee is pleased to announce five new short lectures have been added to our video library! This round of videos cover topics such as finding article publishing charges (APC) costs, changing citation styles in PubMed, contextualizing preprints and more.
Locating Article Publishing Charges (APCs)- In this video, you’ll learn about Article Publishings Charges (APCs), how to find them on a publisher’s website and at the end of the tutorial, receive some tips that will help you handle APCs.
Changing Citation Styles in PubMed- Would you like to learn how to switch from AMA to APA or MLA? This video will focus on changing citation styles when generating citations in PubMed.
Locating Manuscript Guidelines- Learn how to locate manuscript preparation guidelines and author resources for scholarly journals. This tutorial will guide you through three different journal websites to show you where manuscript guidelines are typically located.
Finding Journals with JCR- In this tutorial, you’ll learn about the Journal Citations Report database and how it can help you discover scholarly journals where you can submit your research for publication.
APA Citations for Legal Resources- Are you familiar with the Bluebook legal citation style? Do you want to cite case law, but are unsure of the proper citation format?This video will provide a basic introduction to this citation style used by the APA which is useful when citing legal resources.
These videos and the committee’s other videos from previous lectures are located under the ‘Scholarly Communications Video Tutorials’ tab on the Scholarly Publishing guide. The guide also includes resources to help scholars find a journal that will publish their research, tips on how to spot and avoid predatory publishers, ways to increase the visibility of your published research and more!
The Committee is working on another set of videos that will be released during the fall semester 2022. The committee members are eager for feedback and/or suggestions for video topics. We would love to hear from you! If you have a scholarly publishing topic that you’d like the committee to discuss, please contact the committee chair, Sara Hoover, at shoover@gwu.edu.
A recent report compiled by Ryan Beardsley (Senior Consultant) and Gali Halevi (Director) at the Insitute for Scientific Information, explored the diversity of authorship of STEM publications and found that the ethnicity of authors in the United States has not changed significantly during the past 10 years.
It is widely acknowledged that diversity encourages innovation, improved decision-making, and improved outcomes. Reasons for the continued lack of diversity within higher education mentioned in the report included “insufficient time, funding and knowledge of best practices” (Beardsley & Halevi, 2022).
The report aimed to accomplish the following:
Identify the ethnicity of authors of research articles published in STEM disciplines
Identify the gaps in ethnic diversity within the published research
Discover participation and inclusivity trends of authorship
Discover and identify changes in levels of authorship among underrepresented minorities
The report tracked the ethnicity of authorship using bibliographic authors’ last names as retrieved from articles indexed in Web of Science. Articles selected for inclusion were limited to publications from U.S. institutions authored by U.S. authors. Articles published by organizations outside of the U.S. and/or with international authors were excluded from this analysis. The authors’ last names were extracted from the bibliographic data and compared to U.S. Census data.
Since publishers don’t typically gather ethnicity or demographic data about authors, a system needed to be developed to estimate author ethnicity. Author names were not assigned to a single ethnic group. Author names were “assigned the fractional probability of the respective ethnicities” based upon the frequency of the last name being self-identified within a specific ethnic group in U.S. Census data (Beardsley & Halevi, 2022). For example, if the last name appears in Census data to have self-identified as “90% White Only, 5% Black Only, 2% Asian/Pacific Islands Only, and 3% Two or More Races,” the last name was assigned the same percentage in those same ethnicity categories (Beardsley & Halevi, 2022).
The report selected four areas of research within STEM on which to focus: biochemistry, mathematics, medical research, and computer science. The table below displays the authorship findings for biochemistry and medical research.
2020 Authorship Data
Biochemistry
Medical Research
White Only
41.90%
42.00%
Asian/Pacific Island Only
24.00%
23.00%
Black Only
5.50%
5.50%
Hispanic
5.20%
5.10%
Native American /Alaska Native
0.33%
0.32%
In the discipline of biochemistry, Asian/Pacific Island Only authorship was higher than the representation in the general population. At the same time, Hispanic authorship was significantly underrepresented compared to the representation in the general population.
In medical research, Asian/Pacific Island Only authorship (23% in 2020) was significantly higher than the representation within the general population, while all other ethnicities were underrepresented compared to the general population. White Only authorship continues to make up the largest percentage of published research but has decreased from 45% in 2010 to 42% in 2020.
The conclusions of this report found that there has been very little change in the overall rate of authorship within specific ethnic groups over the past ten years, despite an “increasing awareness of the importance of improved diversity” (Beardsley & Halevi, 2022). The authors recommend increased mentorship, development, and education efforts in this area. They also stated a need for increased collaboration between universities, funding agencies, and publishers. For those interested in learning more, download the full report.
Are you interested in learning more about diversity in STEM? Here are some articles for further reading on this topic: