There are some weeks that I look back and wonder how I felt so busy and got so little done. I was out sick Monday, at the Geo-Resolution conference at SLU all day Tuesday, and gave a talk + led a discussion at a seed manufacturing company yesterday about deep learning and understanding image similarity. Beyond that, I've had a few scattered things this week:
- I put together our CVPPP camera ready submissions (we really need to get better about using the correct template when we create overleaf projects)
- I have continued bouncing ideas around with Hong (why are the low level features so similar??)
- Doing some AWS configuration things for the Temple TraffickCam team (apparently the elastic file system is really slow for serving up images over http?)
- Talking w/ Maya about glitter centroid mapping from scan lines
- Spent some time thinking about what would go into an ICML workshop submission on the generalizability of different embedding approaches: https://docs.google.com/document/d/1NEKw0XNHtCEY_EZTpcJXHwnC3JKsfZIMhZzfU9O0G4I/edit?usp=sharing
I'm trying to figure out how to get better blocks of time going forward to really sit down and really focus on my own research. To that end, the thing I'm excited about right now and don't have a huge update on but managed to actually work on a bit this morning is following on from some conversations with Hong and Robert about how we could use our similarity visualizations to improve the quality of our image retrieval results.
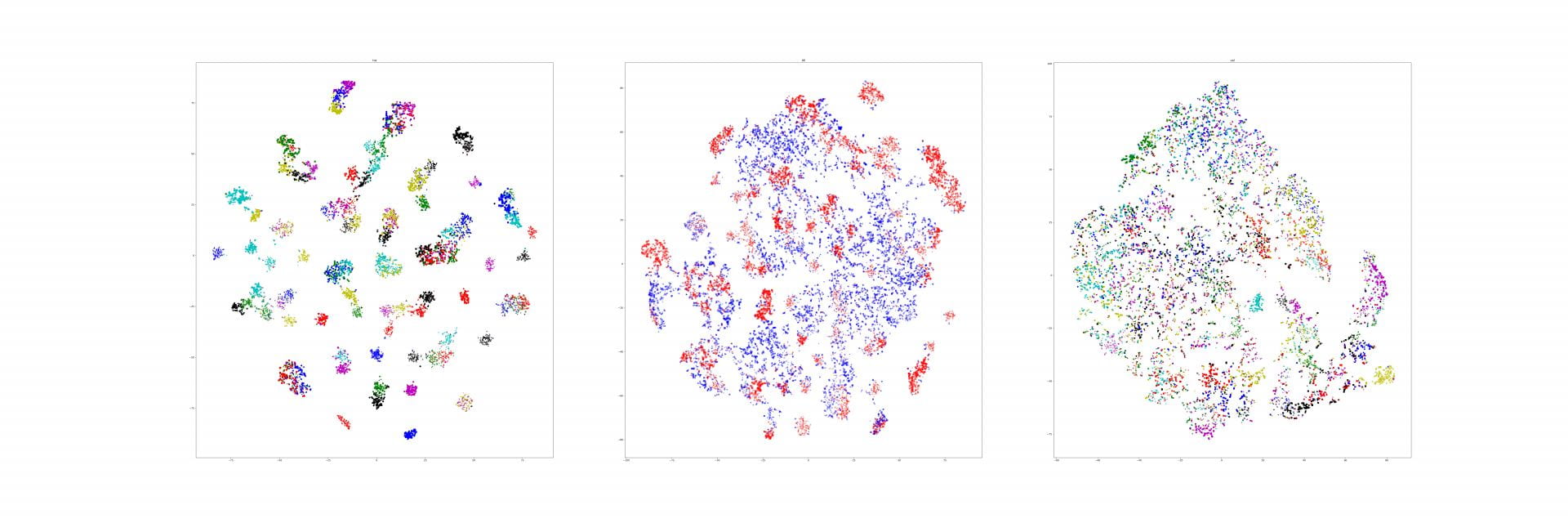
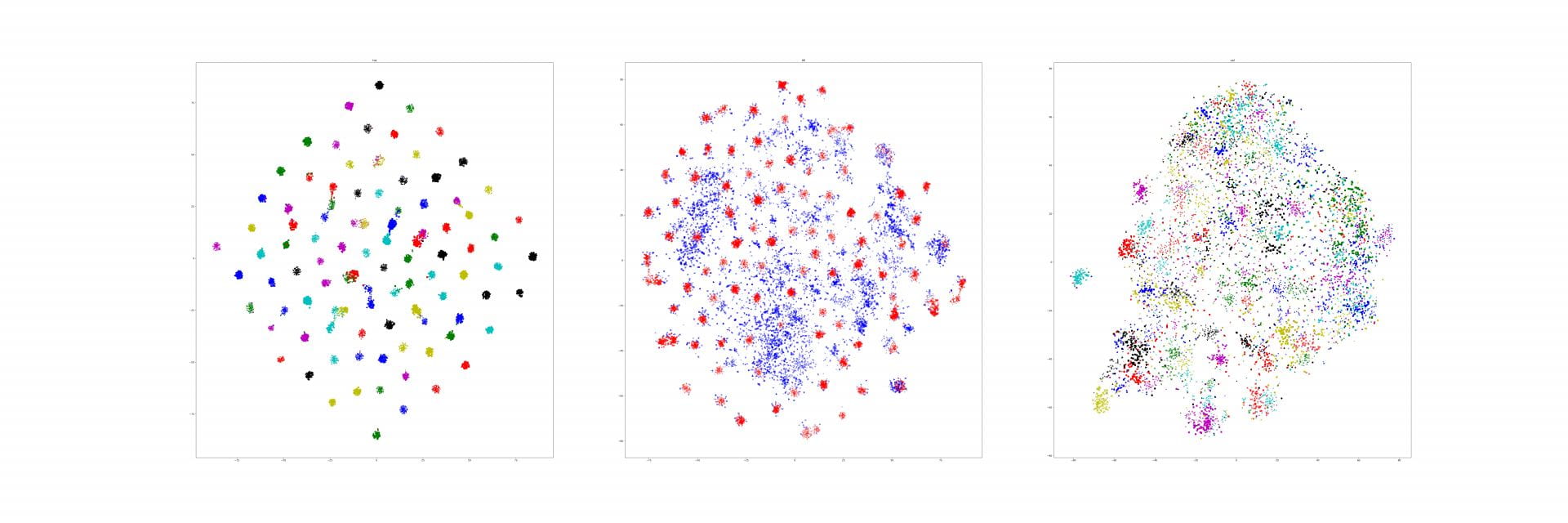
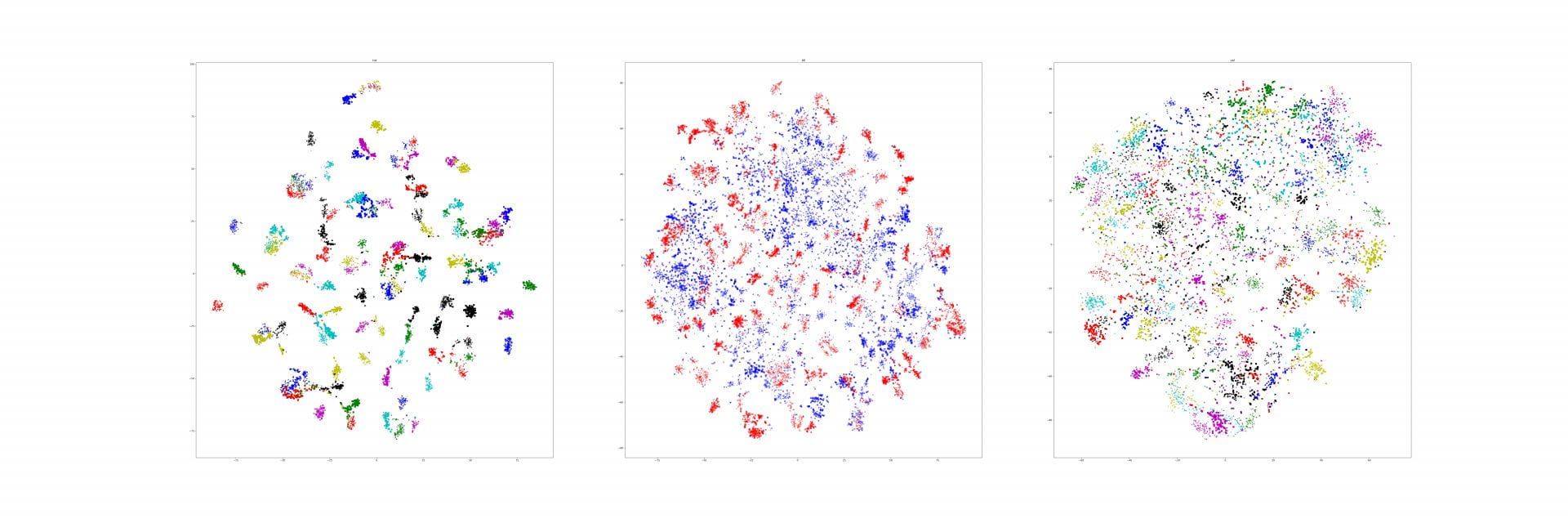
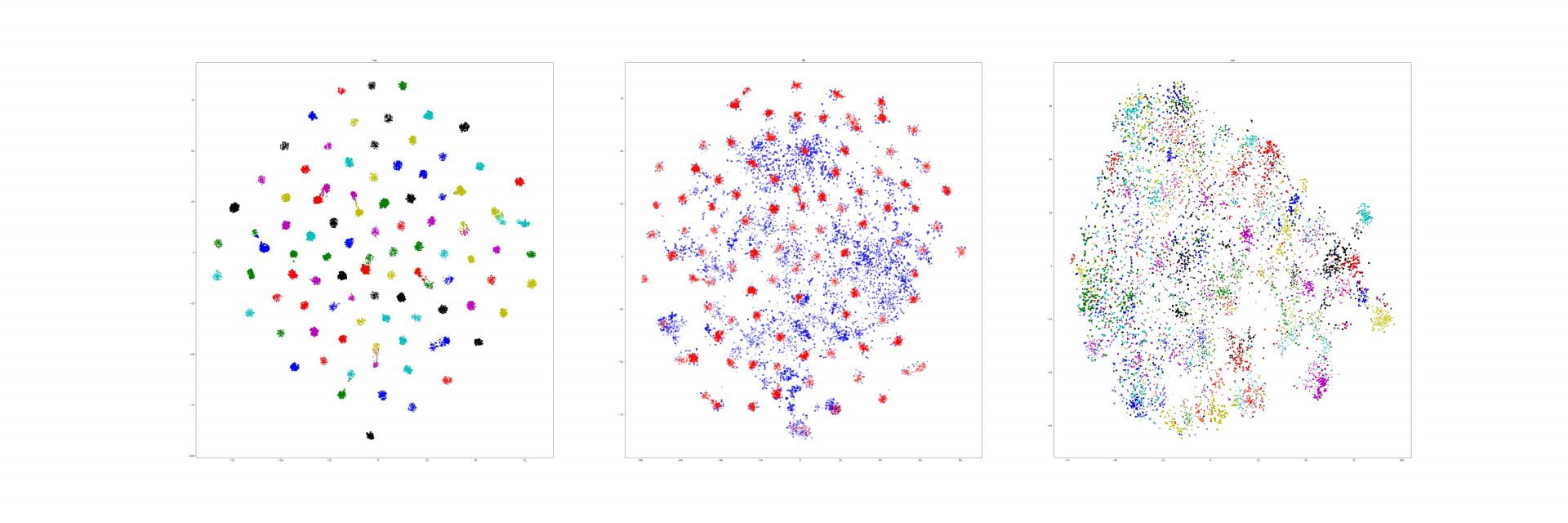
Recall that our similarity visualizations show how much one image looks like another, and vice versa. We additionally know if those images are from the same class or not:

Could you actually use this spatially organized similarity to re-rank your search results? For example, if all of the "correct" heatmap pairs are always concentrated around a particular object, and we see a similarity heatmap that has lots of different, small hotspots, then maybe that's an indicator that that's a bad match, even if the magnitude of the similarity is high.
I don't actually have a great intuition about whether there is something systematic in the heatmaps for correct vs incorrect results, but it's a straightforward enough task to train a binary classifier to predict whether a pair of heatmaps are from a the same class or different classes.
I'm currently generating training data pairs from the cars training set. For every query image, I get the 20 closest results in EPSHN output feature space, and generate their similarity map pairs (each pair is 8x8x2), labeled with whether they're from the same class or not. This produced 130,839 same-class pairs and 30,231 different-class pairs. (A better choice might be to grab only results that are within a distance threshold, but the 20 closest results was an easy way of getting similar but not always correct image pairs).
The next goal is to actually train the binary classifier on these, which, given that we're working with tiny inputs will hopefully not take too long to get to see if it passes the sniff test (I'm actually hoping to maybe have better insight by lab meeting time, but tbd....)