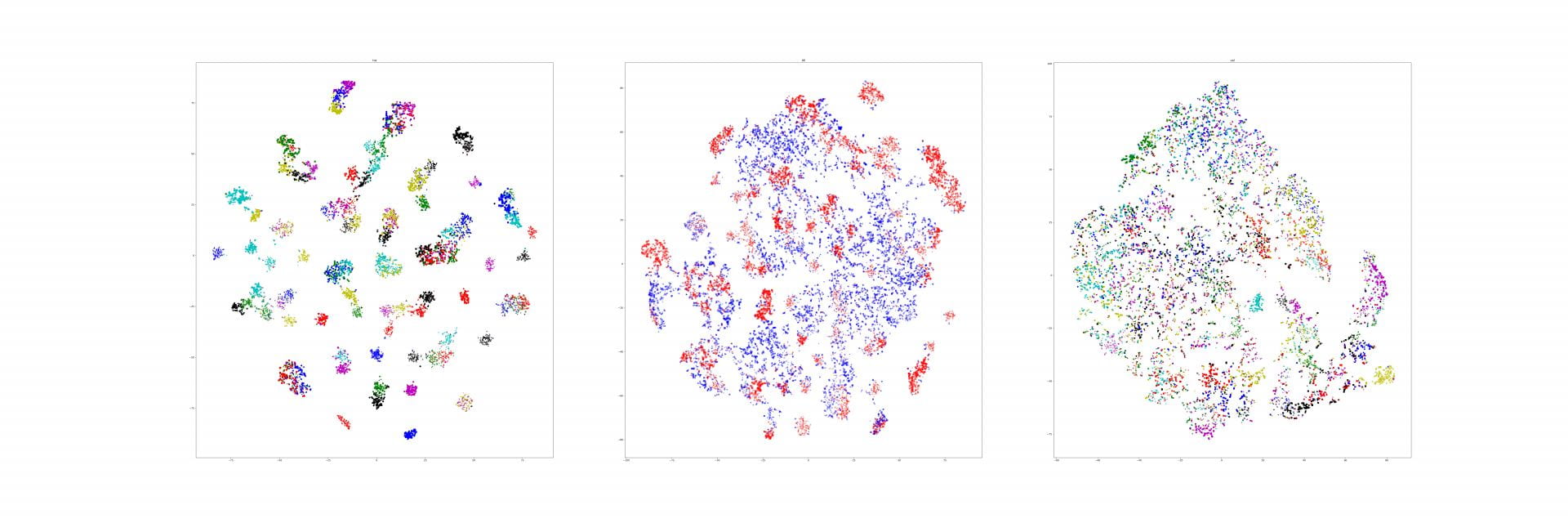
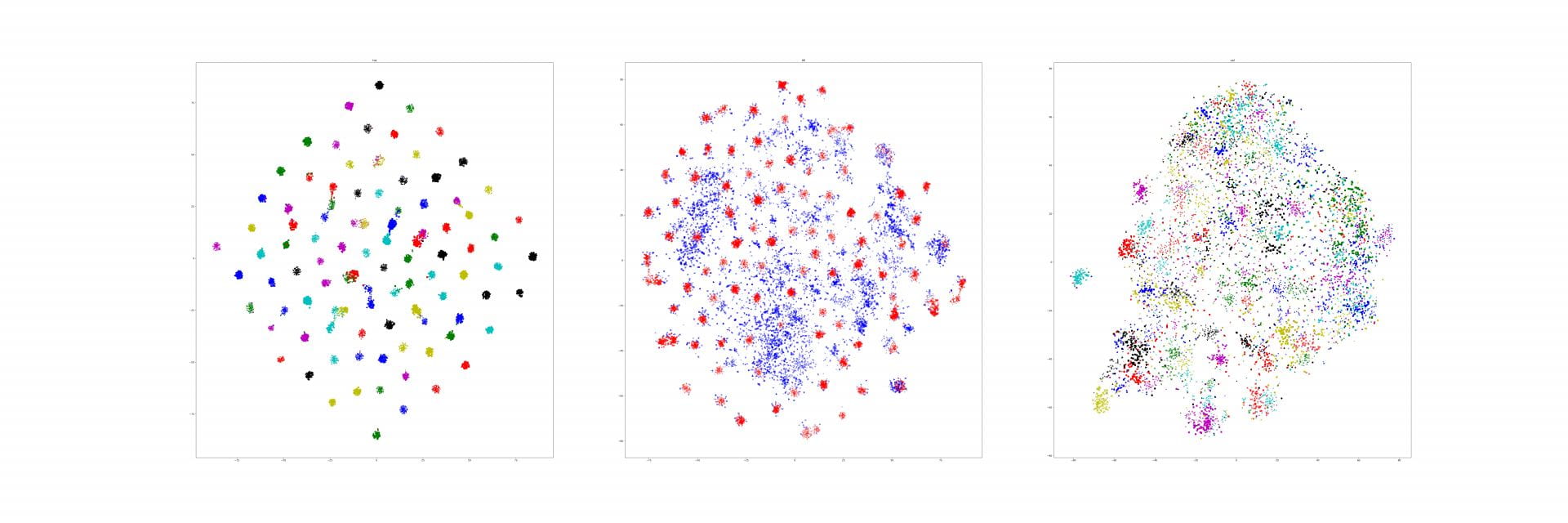
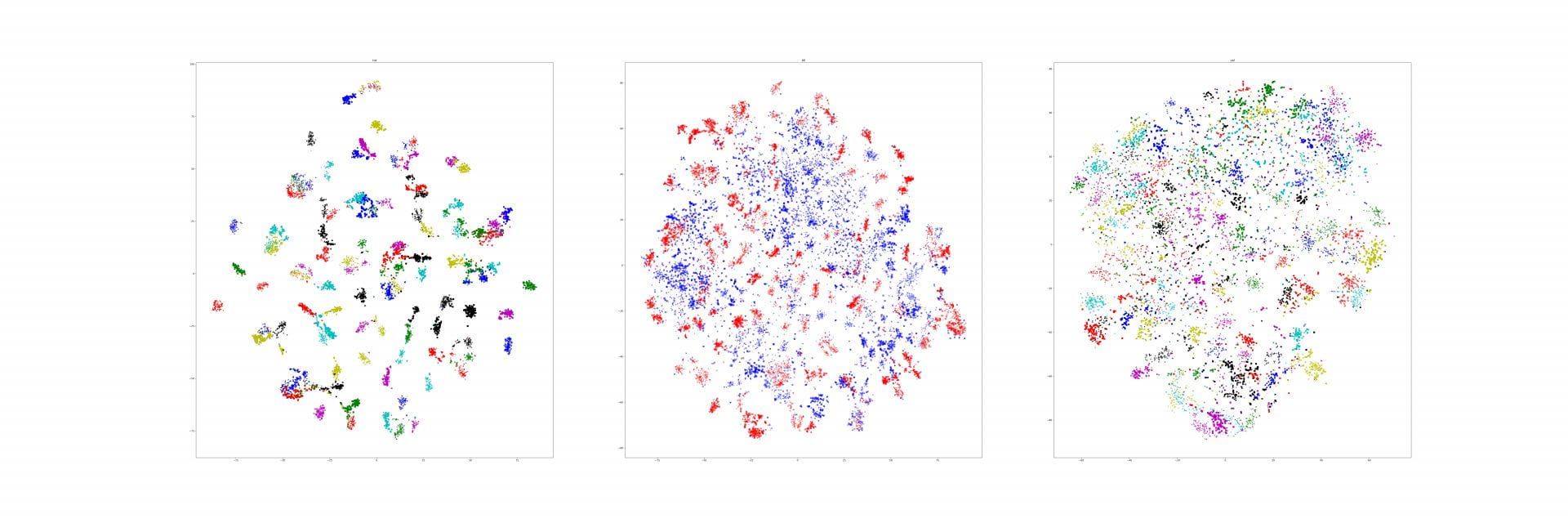
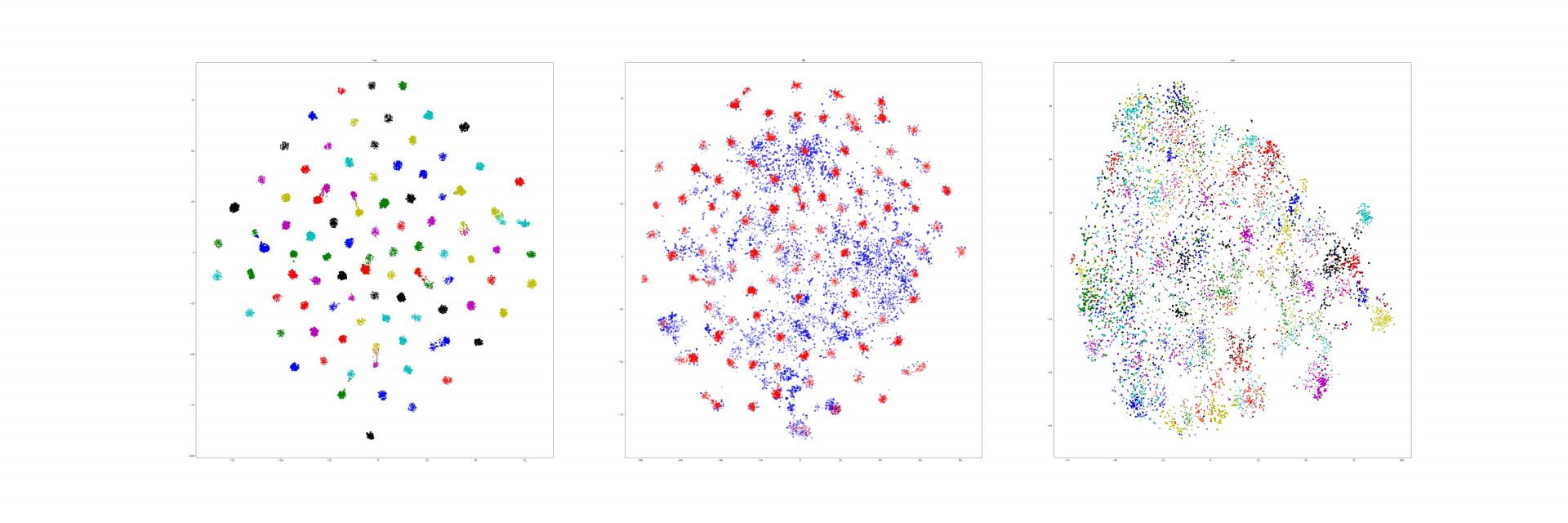
We corrected our experiment from last week.
This time, we selected a subset of the 8x8 grid of the section we wanted (the truck). We then zero'd out the vectors for the rest of the 8x8. We then ran the similarity again, against another image from the same class. Here are the results (left is vector zero'd out besides for those squares determined to be on the truck, right is just another image from the class):
image_0 -> image_15 within the class

image_7 -> image_15 within the class (so we can capture the back of the truck)

So.. kinda? It *seems* like its paying attention to the text, or the top of the truck, but it doesn't seem to care about the back of the truck, which was surprising to us because we thought the back would stay in frame for the longest time.
We thought it might do better on small cars, so we tried this experiment as well:

We've been a little worried that the model is paying attention to the road more than the cars themselves, which this image corroborates?
This prompted another experiment, to see what it thinks about some generic piece of road. We just selected 1 tile of just road, and we wanted to see where it mapped.

Interestingly, the most similar portion was the road right around it, which was very confusing to us as well. Our hypothesis was that this generic piece of road would either: map to itself only (both are uncovered in these 2 pictures), or map to most other pieces of open road. A little miffed by this.