I'm Oliver, a recent CS@GW '22 graduate, staying for a fifth year MS in CS. This summer I'm working with Addy Irankunda for Professor Pless on camera calibration with glitter! I will make weekly(ish) blog posts with brief updates on my work, beginning with this post summarizing my first week.
The appearance of glitter is highly sensitive to rotations. A slight move of a sheet of glitter results in totally different specs of glitter brightening (sparkling!). So if you already knew the surface normals of all the specs of glitter, an image of a sparkle pattern from a known light source could be used to orient (calibrate) a camera in 3D space. Thus we begin by accurately measuring the surface normals of the glitter specs by setting up a rig with camera, monitor for producing known light, and glitter sheet.
Let's get into it. Here's an image of glitter.

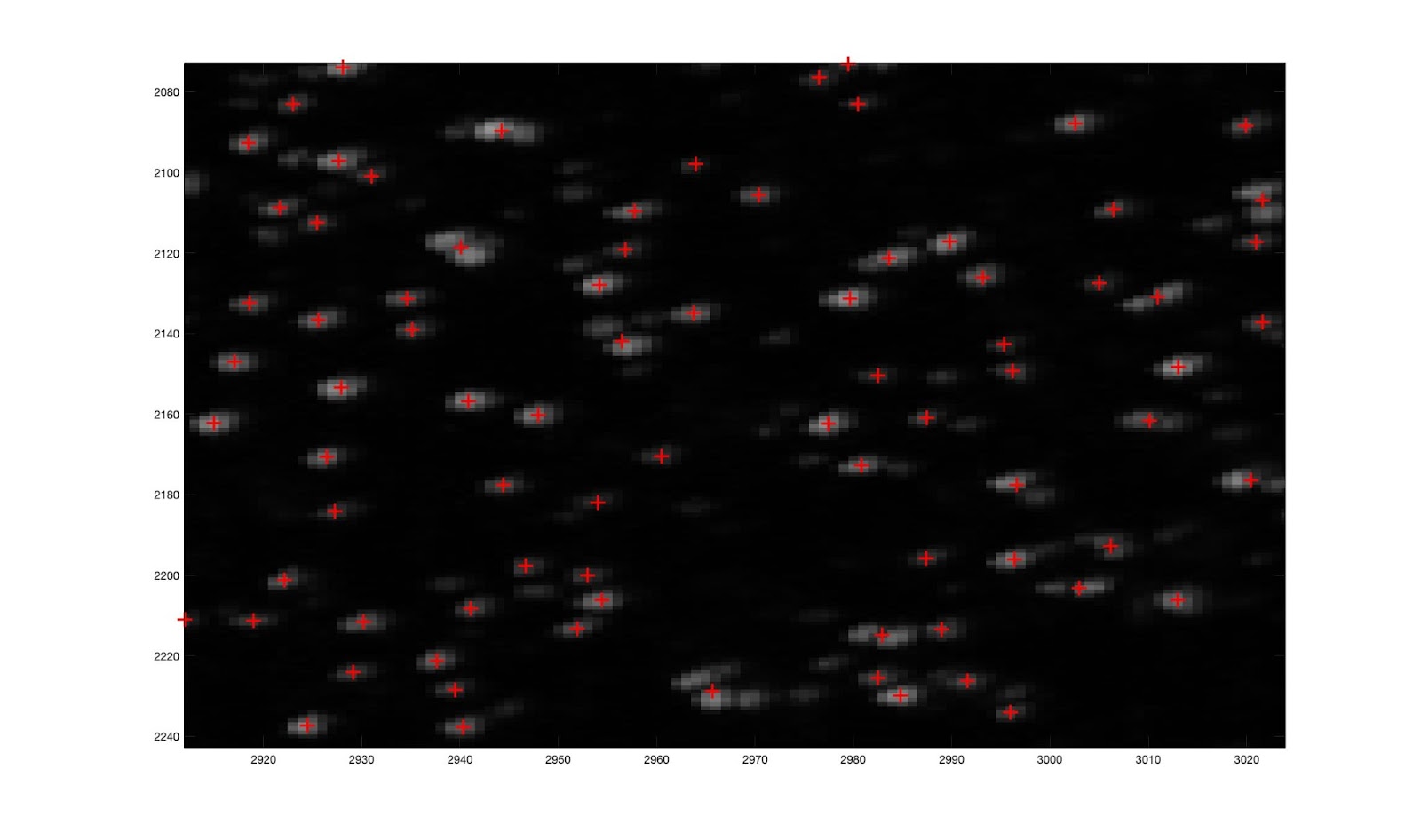
First, we need to find all the glitter specs from many such images (taken as a vertical bar sweeps across the monitor). We build a max-image where each pixel is the brightest among those across all the images. We then filter (narrow gaussian minus wide gaussian) which isolates just small bright points otherwise surrounded by darkness (like sparkling glitter specs). Finally, we apply a threshold to the filtered image. Here is the result at the end of that process.

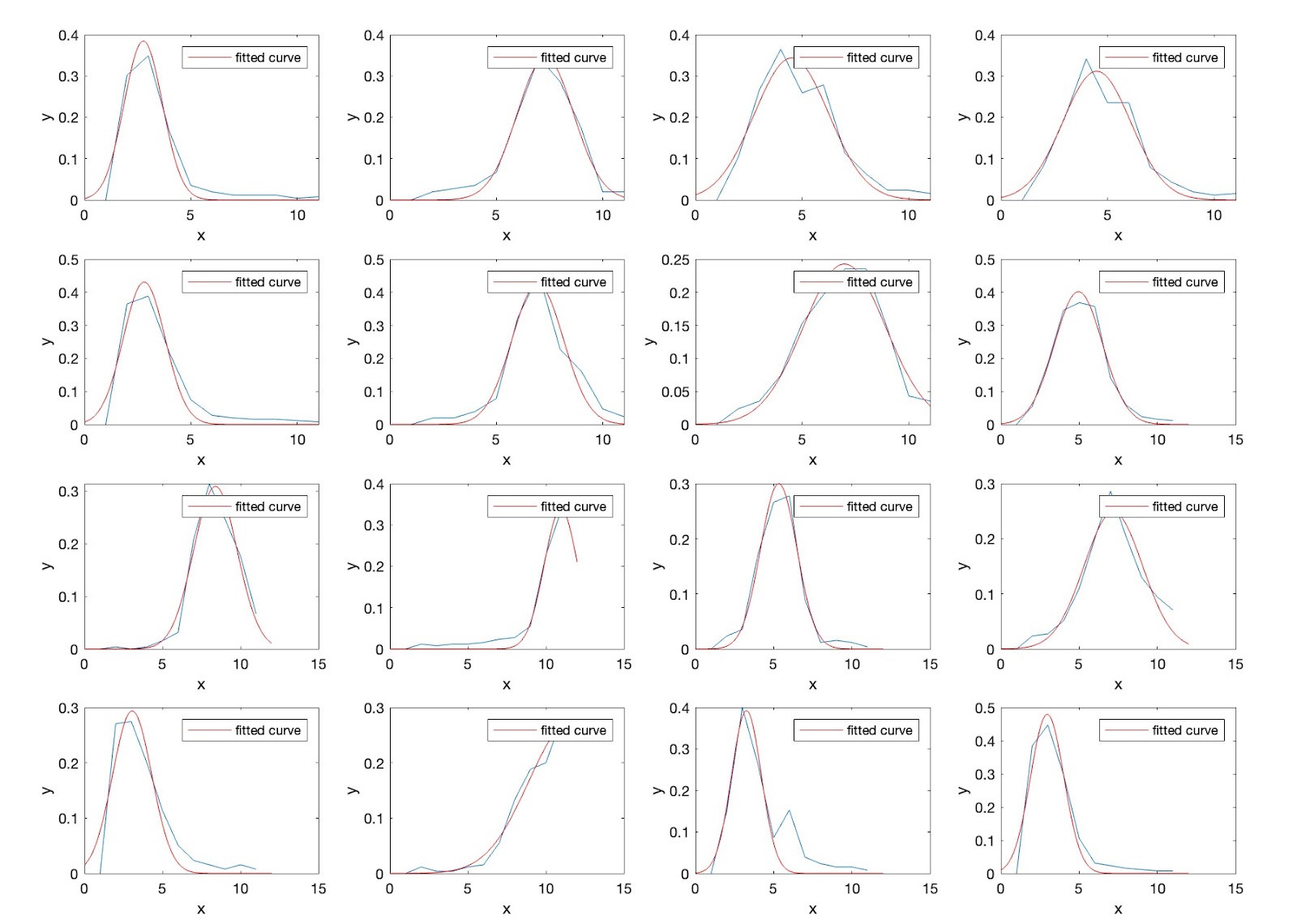
These little regions have centroids that we can take for now as the locations of the glitter specs. We expect that as the vertical bar (which itself is Gaussian horizontally) should produce Gaussian changes in brightness of the glitter specs as it moves across their perceptive field. Here are a bunch of centroids' brightnesses over the course of several lighting positions with fitted Gaussians.
So far these have been test images. To actually find the glitter specs' surface normals, we'll need to measure the relative locations of things pretty precisely. To that end, I spent some time rigging and measuring on the optical table a set up. It's early, and we need some other parts before this gets precise, but as a first take, here is how it looks.

The glitter sheet is on the left (with fiducial markers in its corners) and the monitor with camera peering over are on the right. Dark sheets enclose the rig when capturing. The camera and monitor are operated remotely using scripts Addy wrote.
First attempts at full glitter characterization (finding the specs and their surface normals) is right around the corner now. One thing to sort out is that for larger numbers of images, simply taking the max of all the images leads to slightly overlapping bright spots. Here's an example of some brightnesses for random specs. Notice that number 7 has two spikes, strangely.
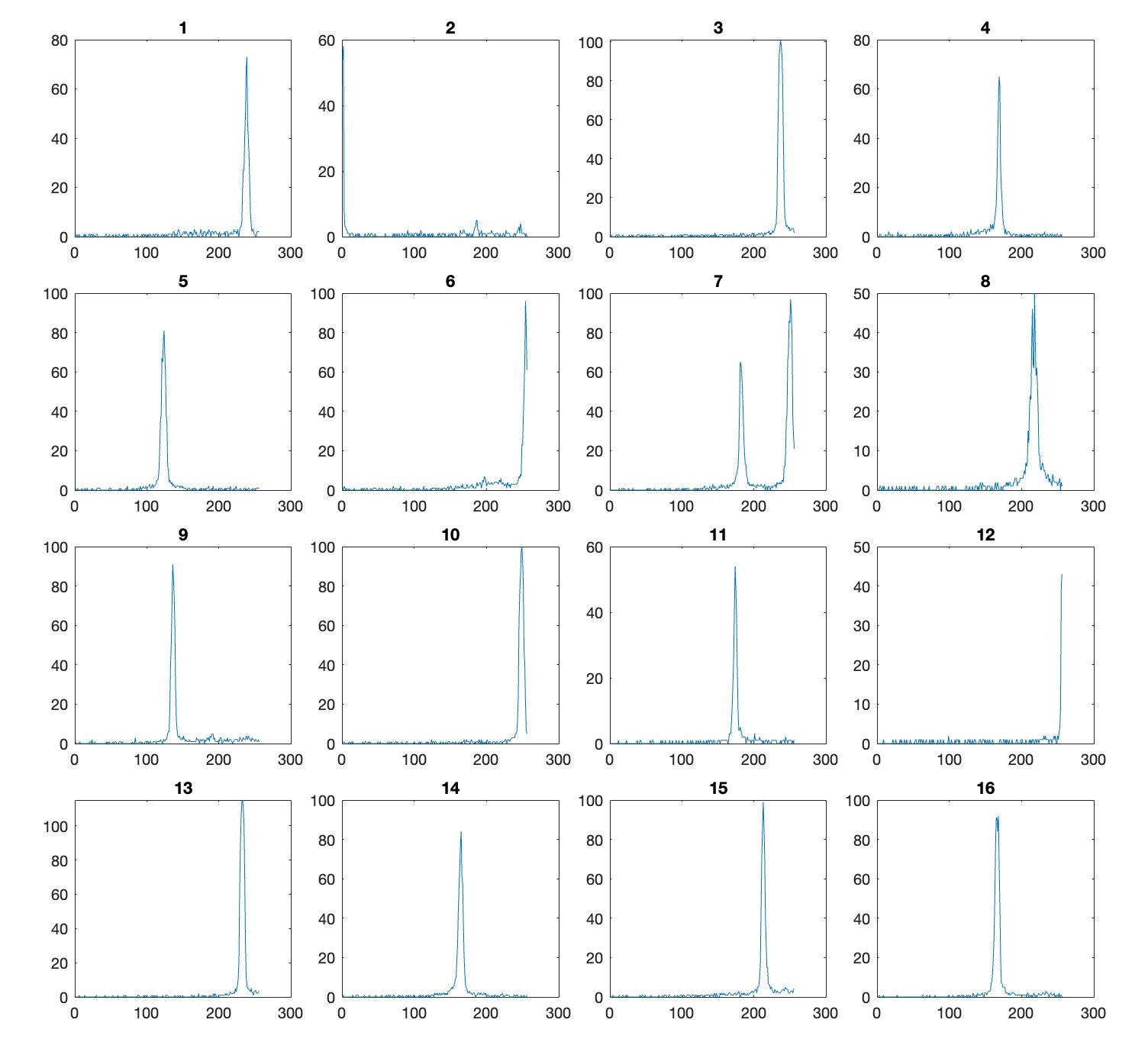
Sure enough, when you go to look at that spec's location, it is a centroid accidentally describing two specs.


This image gives some sense of how big a problem this is... worth dealing with.
I am now pressing forward with improving this spec-detection and also with making the rig more consistent and measurable. Glitter characterization results coming soon...
















