TL;DR: We want to predict CLIP's zero-shot ability by only seeing its text embedding space. We made two hypotheses:
- CLIP’s zero-shot ability is related to its understanding of ornithological domain knowledge, such that the text embedding of a simple prompt (e.g., "a photo of a Heermann Gull") aligns closely with a detailed descriptive prompt of the same bird. (This hypothesis was not supported by our findings)
- CLIP’s zero-shot ability is related to how well it separates one class's text embedding from the nearest text embedding of a different class. (This hypothesis showed moderate support)
Hypothesis 1:
Motivation
How would a bird expert tell the difference between a California gull and a Heermann's Gull?

A California Gull has a yellow bill with a black ring and red spot, gray back and wings with white underparts, and yellow legs, whereas a Heermann's Gull has a bright red bill with a black tip, dark gray body, and black legs.
Experts utilize domain knowledge/unique appearance characteristics to classify species.
Thus, we hypothesize that, if the multimodal training of CLIP makes CLIP understand the same domain knowledge of experts, the text embedding of "a photo of a Heermann Gull" (let's denote it asplain_prompt(Heermann Gull)) shall be close (and vice versa) to the text embedding of "a photo of a bird with Gray body and wings, white head during breeding season plumage, Bright red with black tip bill, Black legs, Medium size. Note that it has a Bright red bill with a black tip, gray body, wings, and white head during the breeding season." (let's denote it as descriptive_prompt(Heermann Gull)).

For example, the cosine similarity between the two prompts of the Chuck-will's-widow is 0.44 (lowest value across the CUB dataset), and the zero-shot accuracy on this species is precisely 0.
Then, we can formulate our hypothesis as follows

We tested our hypothesis in the CUB dataset.
Qualitative and Quantitative Results

The cosine similarity between "a photo of Yellow breasted Chat" and "a photo of a bird with Olive green back, bright yellow breast plumage" is 0.82, which is the highest value across the whole CUB dataset. However, the zero-shot accuracy on this species is 10% (average accuracy is 51%)
We got the Pearson correlation coefficient and the Spearman correlation coefficient between accuracy and the text embedding similarity as follows:
- Pearson correlation coefficient = -0.14, p-value: 0.05
- Spearman correlation coefficient = -0.14 p-value: 0.05
The coefficients suggest a very weak linear correlation.
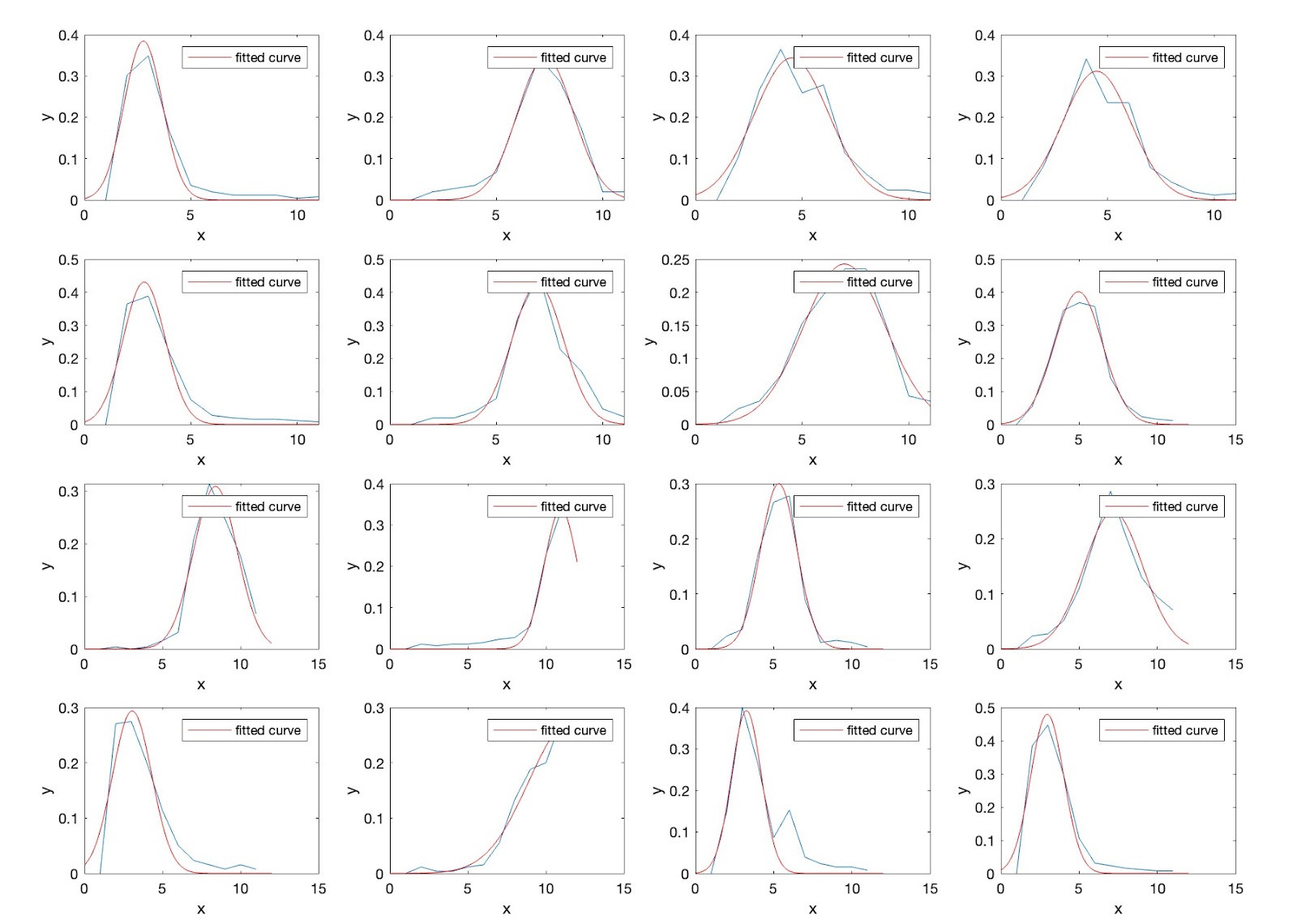
We also make a line plot of accuracy vs. text embedding similarity, which shows no meaningful trends (maybe we can say the zero-shot accuracy tends to zero if the text embedding similarity score is lower than 0.50):

Thus, we conclude that the hypothesis is not supported.
I think there are possibly two reasons:
- The lack of correlation might be due to the nature of CLIP's training data, where captions are often not descriptive
- CLIP does not utilize domain knowledge in the same way humans do
Hypothesis 2
Motivation
We examine the species with nearly zero CLIP accuracy:

We can see that they are close in appearance. Therefore, we wonder if their text embeddings are close as well.
More formally, we want to examine the cosine similarity between one species' text embedding and its nearest text embedding to see if CLIP's inability to distinguish them at the semantic level possibly causes the classification to fail.
Qualitative and Quantitative Results
We also got the Pearson correlation coefficient and the Spearman correlation coefficient:
- Pearson correlation coefficient = -0.43 p-value: 1.3581472478043406e-10
- Spearman correlation coefficient = -0.43 p-value: 1.3317673165555703e-10
which suggests a significant but moderate negative correlation.
And a very noisy plot ......

Wait, what if we smooth the line plot by averaging every 20 points to 1 point:

The trend looks clearer, although there is still an "outlier."
In conclusion, I think we can't determine whether CLIP's zero-shot without giving the information/context of other classes. For example, CLIP completely failed to classify a California gull vs. a Heermann's Gull, while it perfectly solves the problem of, e.g., a banana vs. a Heermann's Gull.
Next step, I want to investigate:
- Are there some special local geometry properties that are related to the zero-shot ability?
- When and why does CLIP's zero-shot prediction fail? Is it because the image encoder misses the detailed high-resolution features, or is it because the text encoder fails to encode the most "unique" semantic information. Or maybe it is just because we need a larger model to align the image embedding space and the text embedding space.