In this post, I am going to run through everything that I have tried thus far, and show some pictures of the results that each attempt has rendered. I will first discuss the results of the experiments involving a set of vertically co-linear glitter, 10 centroids. Then, I will discuss the results of the experiments involving 5 pieces of glitter placed in a circle around the camera & light, such that the camera & light are vertically co-linear.
Calculation of Coefficients
In order to account for the surface normals having varying magnitudes (information that is necessary in determining which ellipse a piece of glitter lies on), I use the ratios of the surface normal's components and the ratios of the gradient's components (see previous post for derivation).
Once I have constructed the matrix A as follows:
A = [-2*SN_y * x, SN_x *x - SN_y *y, 2*SN_x *y, -SN_y, SN_x], derived by expanding the equality of ratios and putting the equation in matrix form. So, we are solving the equation: Ax = 0, where x = [a, b, c, d, e]. In order to solve such a homogeneous equation, I am simply finding the null space of A, and then using some linear combination of these vectors to get my coefficients:
Z = null(A);
temp = ones(size(Z,2),1);
C = Z*temp
Using these values of coefficients, I can then calculate the value of f in the implicit equation by directly solving for it for each centroid.
1. Glitter is vertically co-linear

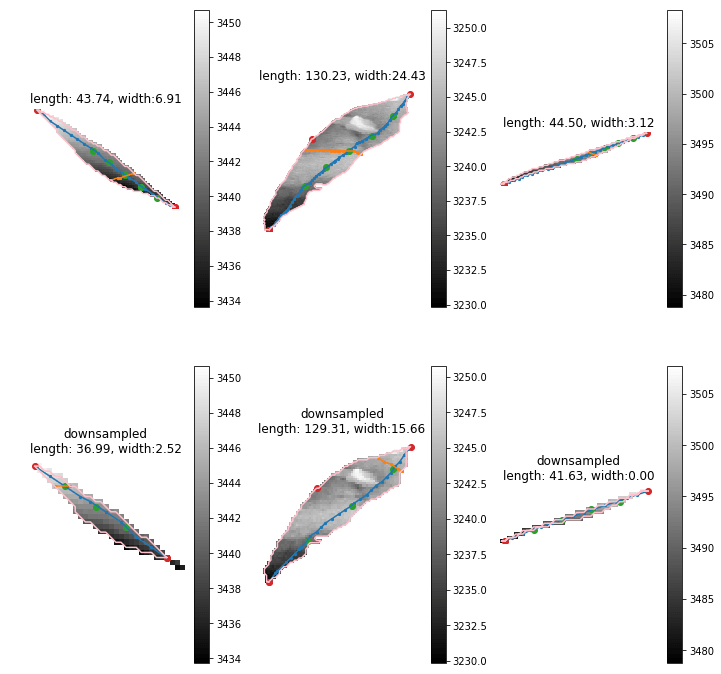
For the first simulation, I placed the camera and light to the right of the glitter line, and vertically co-linear to each other, as seen in the figure to the left. Here, the red vectors are the surface normals of the glitter and the blue vectors are the tangents, or the gradients, as calculated based on the surface normals.
- Using the first 5 pieces of glitter:
- Coefficients are as follows:
- a = -0.0333
- b = 0
- c = 0
- d = 0.9994
- e = 0
- No plot - all terms with a y are zeroed out, so there is nothing to plot. Clearly not right...
- Using the last 5 pieces of glitter:
- Same results as above.
This leads me to believe there is something unsuitable about the glitter being co-linear like this.
 For the second simulation, I placed the camera and the light to the right of the glitter line, but here they are not vertically co-linear with each other, as you can see in the figure to the left.
For the second simulation, I placed the camera and the light to the right of the glitter line, but here they are not vertically co-linear with each other, as you can see in the figure to the left.
- Using the first 5 pieces of glitter:
- Coefficients are as follows:
- a = 0.0333
- b = 0
- c = 0
- d = -0.9994
- e = 0
- No plot - all terms with a y are zeroed out, so there is nothing to plot. Clearly not right...
- Using the last 5 pieces of glitter:
- Same results as above.
If we move the camera and light to the other side of the glitter, there is no change. Still same results as above.
2. Glitter is not vertically co-linear
 In this experiment, the glitter is "scattered" around the light and camera as seen in the figure to the left.
In this experiment, the glitter is "scattered" around the light and camera as seen in the figure to the left.
I had a slight victory here - I actually got concentric ellipses in this experiment when I move one of the centroids so that it was not co-linear with any of the others:

In the process of writing this post and running through all my previous failures, I found something that works; so, I am going to leave this post here. I am now working through different scenarios of this experiment and trying to understand how the linearity of the centroids affects the results (there is definitely something telling in the linearity and the number of centroids that are co-linear with each other). I will try to have another post up in the near future with more insight into this!