Tuesday and Wednesday I sat in a building in Ballston VA  (just a few metro stops away) for the "Phase 2 kickoff meeting" for the Geo-spatial Cloud Analytics program. James is leading our efforts towards this project, and our goal is to use nearly-real-time satellite data to give updates traversability maps in areas of natural disasters (e.g. Think "Google maps routing directions that don't send you through flood waters).
(just a few metro stops away) for the "Phase 2 kickoff meeting" for the Geo-spatial Cloud Analytics program. James is leading our efforts towards this project, and our goal is to use nearly-real-time satellite data to give updates traversability maps in areas of natural disasters (e.g. Think "Google maps routing directions that don't send you through flood waters).
Special note 1: Our very own Kyle Rood is going to be interning there this summer, working on this project!
Many of the leaders of teams for this project "grew up" the same time I did ... when projects worked with thousands of points and thousands of lines of matlab code. Everyone is now enamored with Deep Learning.... and share stories about how their high-school summer students do amazing things using the "easy version" of Deep Learning, using mostly off the shelf tools.
The easy version of Deep Learning relies on absurd amounts of data; and this project (which considers satellite data) and absurdly absurd amounts of data. In the Houston area, we found free LIDAR from 2018 that, when rendered, looks like this:
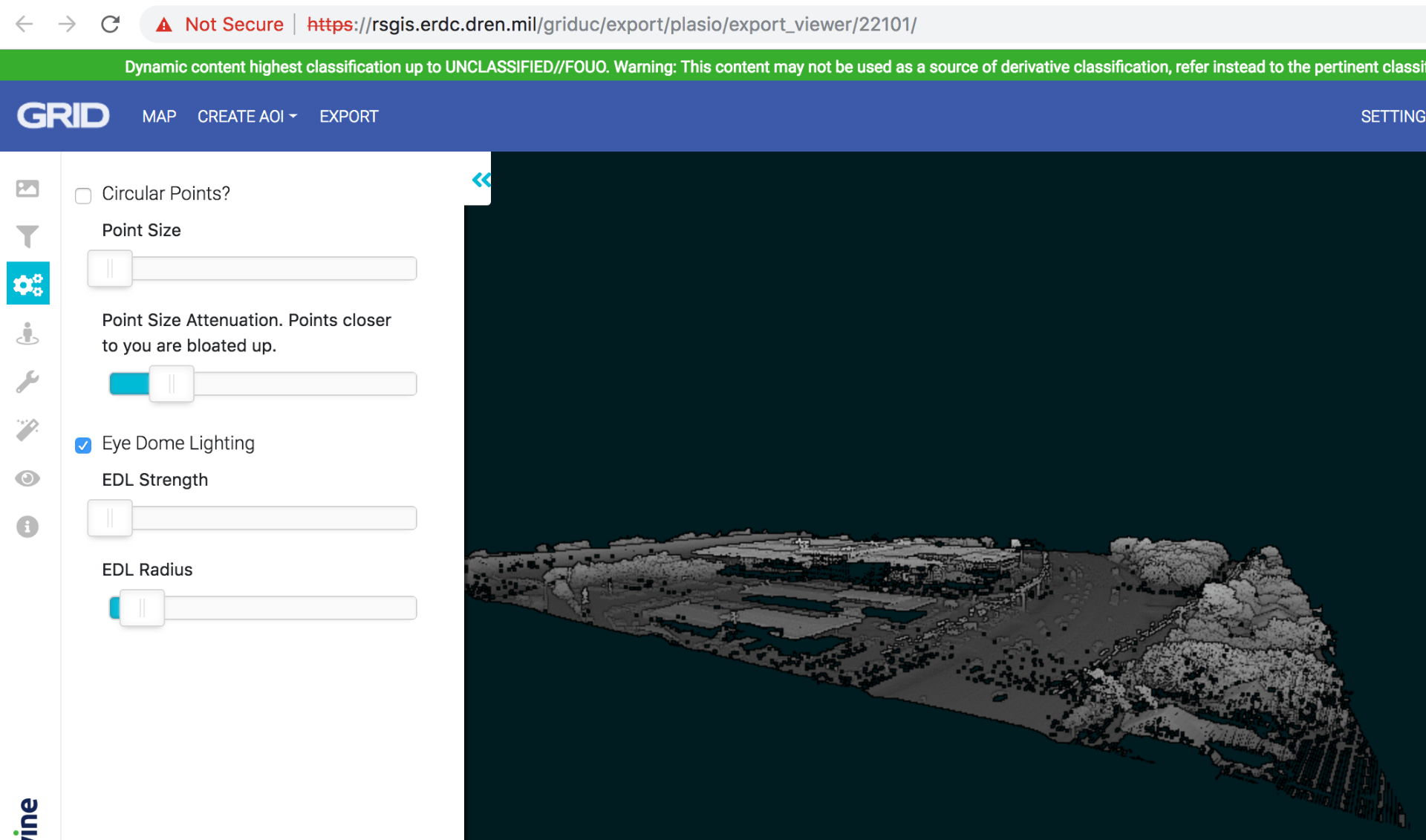
and zooming in:

This scale of data (about 15cm resolution LIDAR) is available for a swath that cuts across Houston.
This data is amazing! and there is so much of it. Our project has the plan to look at flooding imagery and characterize which roads are passible.
We've always known the timeline of this project was very short; but we have an explicit demo deadline of November (which means we need to deliver our code to DZyne much sooner). So:
(a) we may consider first run options that do less learning and rely more on high-resolution or different data types to start, and
(b) the satellite data is *amazing* and we should think about which of our algorithms might be effective on these datatypes as well.