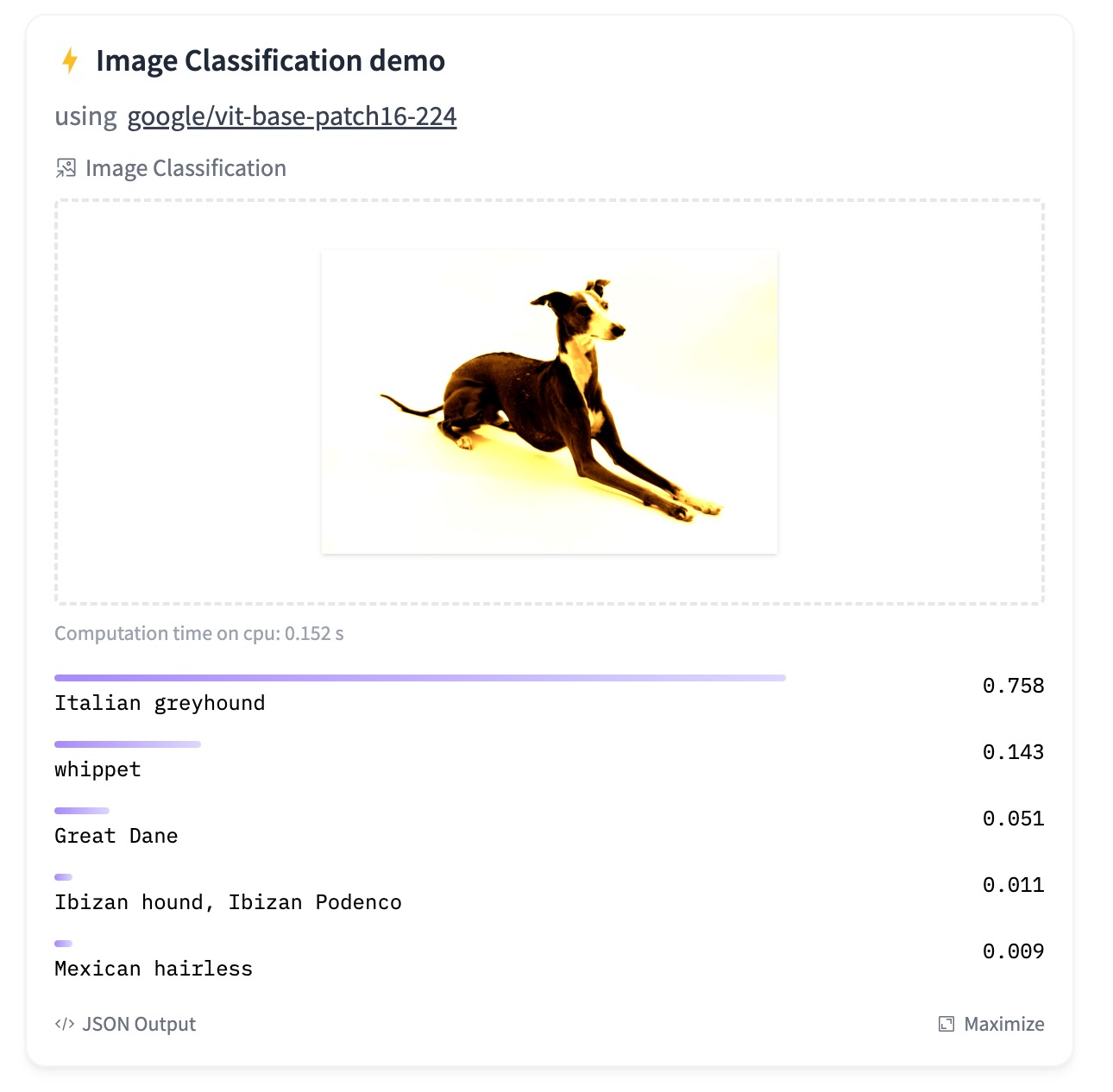
Stereograms are a fascinating visual phenomenon that has captivated audiences for centuries. Although their popularity has waned over time, the underlying principles continue to intrigue. Originally, stereograms were designed to create an illusion of depth from a flat image, effectively tricking the brain into seeing a three-dimensional scene. This optical illusion is achieved by manipulating the viewer’s depth perception through subtle visual cues. As we delve into the possibilities offered by computer vision technology, we can appreciate the unique applications of stereograms across various fields. Their ability to transform two-dimensional visuals into three-dimensional experiences highlights their potential as a tool for enhancing visual perception and creating engaging imagery.
Here is an example of a stereogram image to give you an idea of how a stereogram based on an original image might appear. This sample stereogram provides a visual representation of how the 3D effect is achieved using depth maps and patterns.


Give a moment or two to see the 3D image of an animated version of an airplane in the stereogram image. This is how stereogram image looks like.
We provided three images: one featuring a black hole, another depicting a camel, and the third showcasing a coke glass bottle. We selected these images for various reasons. Firstly, the black hole image was chosen to challenge viewers and provide a unique experience. We thought it would be really unique to see a black hole in 3D, mainly because we can’t forever wait on NASA to show us a 3D rendering of a black hole. So we decided to take matters into our own hands. Secondly, we utilized DALLE to generate an image of a camel in a desert at sunset, which we found particularly striking and engaging. This choice was made to create a scenic and captivating depiction of a camel in its natural habitat. The third image is a straightforward depiction of a bottle. Our curiosity led us to explore how a bottle would appear in a stereographic 3D image. So we have implemented a computer vision algorithm to create a stereographic image for these three images.
Here are the images that we’ve used to test the creation of a stereogram image.



Creating an autostereogram is very exiting and fun to create, before delving into the impementation of a computer vision algorithm to create a stereogram image, ever pondered the fact that how the stereogram images are created. Creating an autostereogram image, also known as a Magic Eye image, requires specific tools and techniques to generate the hidden 3D effect without the need for special glasses or crossing/relaxing your eyes.
The initial step involves generating a depth map of the image, followed by selecting a repeating pattern that will define the structure of your autostereogram. Later combining the depth map and the repeating pattern so that the brightness values of the depth map will determine how the pattern is distorted or shifted to create the 3D effect.
Why is depth map important and how it is useful in the creation of stereographic images ?
A depth map provides the necessary depth information required to generate the illusion of 3D depth perception in a 2D image. A depth map is a grayscale image where each pixel’s intensity represents the distance of the corresponding point in the scene from the viewer’s perspective. Brighter areas indicate objects that are closer, while darker areas represent objects that are farther away. In the process of creating an autostereogram, a repeating pattern is manipulated according to the depth map. The depth map dictates how much to shift or distort the repeating pattern across different parts of the image. Closer objects in the depth map will cause more distortion in the pattern, while farther objects will cause less distortion. These are the important things in creation of a stereographic image. As the viewer’s eyes try to focus on the repeating patterns, the variations caused by the depth map force the eyes to adjust. This adjustment mimics the natural binocular disparity (the slight difference in images between the two eyes due to their horizontal separation) which is how depth perception occurs in normal vision. The brain interprets these manipulations in the pattern as spatial variations, thus perceiving a 3D scene.
Using a computer vision algorithm we have converted the above images to its corresponding depth map and the results are displayed below.



Using the provided depth map, it becomes straightforward to interpret the depth perception of the images. For instance, consider a depth map of a black hole: the ring of light surrounding the black hole appears closer to the observer compared to the black hole itself. As mentioned above the darker areas represents the objects that are far away like the black hole itself and the lighter area: the ring of light that surrounds the black hole appear closer to the observer. The same principle applies to the other mentioned depth maps as well. Each depth map illustrates the relative distances and depth perceptions within the depicted scenes.
After creating the depth maps, we used another computer vision algorithm to create a stereographic images using the above depth map images with a pattern image.
Here are the stereogram images by using the above depth map:

This is a stereogram of a black hole. Take a moment or two to perceive the hidden 3D image within it.
This is a stereogram of a camel. Take a moment or two to perceive the hidden 3D image within it.


This is a stereogram of a bottle. Take a moment or two to perceive the hidden 3D image within it.
So, this is the conventional process for creating a stereographic image using a given image and its corresponding depth map. However, to innovate and add variety to this approach, we have decided to introduce a new method. Our idea involves converting normal images into ASCII art representations, then transforming them into corresponding depth maps to capture depth perception, and finally converting them into stereographic images. This unique approach aims to bring a fresh perspective and creative twist to stereogram creation.
We utilized an algorithm to transform the original image into an ASCII character representation, and the images are given below.



The ASCII representation of a black hole is distinctly clear, showing an almost precise depiction of the black hole. In contrast, the ASCII representation of a scenic view featuring a camel appears dense because the surrounding pixels have similar lightness values, making the camel less distinguishable. Lastly, the ASCII representation of a bottle is sharply visible and recognizable.
Now we have produced depth maps for these ASCII images, which appear quite pixelated. Let’s examine the depth map for each ASCII image individually.
Here is the depth map for the ASCII representation of a black hole. Observe that the brighter ring of light, which is closer to the observer, contrasts with the darker black hole and background, indicating their larger distance from the observer.


Here is the depth map corresponding to the ASCII representation of a camel in a scenic view. Similar to the ASCII image, the camel is not clearly visible in this depth map due to its density and the surrounding pixel values.
Here is the depth map corresponding to the ASCII representation of a bottle. This depth map provides a clear analysis of depth perception.
In the original bottle image, the middle section appears closer compared to the top and bottom due to its bulging shape. Consequently, in this depth map, the middle part is brighter, indicating proximity, while the background is darker, representing farther distance from the observer.

After converting the depth-map images, we transformed them into their corresponding stereogram images. The stereographic images are given below.



It can be quite challenging and time-consuming to identify the hidden 3D image within stereogram images. Sometimes, it’s even impossible to discern the hidden 3D image. To verify if the stereogram images are functional, we used an online tool to check for any hidden 3D image. The results of this analysis are provided below.



Our approach involves converting original images into ASCII representations, followed by generating corresponding depth maps and ultimately transforming them into stereographic images using computer vision algorithms. Unlike alternative methods that directly use computer vision algorithms for stereogram generation based on depth maps or patterns, our approach introduces an additional layer of complexity by initially converting images into ASCII character representations. This unique twist with ASCII characters adds complexity, making it more challenging to perceive the hidden stereographic images within our creations.
We were curious to know if AI tools like DALL-E, ChatGPT-4, or other image-generating AI models could create stereogram images. To explore this, we prompted ChatGPT-4 with various requests to generate a stereogram image. However, ChatGPT-4, being an image-generating tool, couldn’t directly generate stereogram images. Instead, it provided steps on how to create stereogram images. We uploaded an image of a black hole and requested ChatGPT-4 to convert it into a stereogram image. However, the response we received was not a stereogram image but rather instructions or guidance on how to generate a stereogram image. We went to BingAI and posed the same question that we asked ChatGPT-4, It produced an image with patterns, but it wasn’t a stereogram image.


Therefore, the AI tool currently lacks the capability to generate stereogram images, despite its ability to generate other types of images.
Throughout this project, we utilized a diverse array of tools and resources, including specialized computer vision algorithms designed for image processing and transformation. Our approach was inspired by established stereogram generation techniques while also exploring innovative methods to integrate ASCII representations into the workflow. We leveraged online repositories and tutorials focused on computer vision techniques to inform and refine our process. We have delved further into understanding the mechanics behind stereogram generation by referencing Frolian’s blog post titled “Making Your Own Autostereograms using Python.” Through this exploration, we gained insights into identifying optimal patterns.
By incorporating these advanced algorithms, we ventured into new realms of creativity and visual perception, pushing the boundaries of stereogram artistry to a higher level of complexity and fascination. Whether unraveling the intricate patterns embedded within ASCII characters or appreciating the illusion of depth in stereographic images, this fusion of technology and artistic expression opens up endless possibilities for exploration and experimentation.
We have also shared several other stereogram images below for you to try guessing what each image depicts or identify the hidden 3D image present within them. Please feel free to comment below with your observations and guesses.



This blog post was created by Parithosh Dharmapalan and Pooja Srinivasan.